みんな大好き「VLOOKUP関数」を高速化しようというお話です。
VLOOKUPの高速化手法は、
- 簡単!わかりやすくてそこそこ高速
- 超高速!ただし使用条件あり
この2パターンがあります。
どちらも使いこなせばとても便利ですので、
是非習得していってください。
《簡単》データが連続していることを活用した高速化
まずは「簡単!わかりやすくてそこそこ高速」パターンから。
ひとまずイメージしやすいように、

| B2 | =VLOOKUP(A2,くだもの価格表!A:B,2,FALSE) |
|---|
これを計算することにします。なじみのある式ですね。
※参照するくだもの価格表は別シートを想定
さてこれを高速化するとこうなります。
| B2 | =IF(A2=A1,B1,VLOOKUP(A2,くだもの価格表!A:B,2,FALSE)) |
|---|
理屈は簡単で、
「同じ商品が連続した場合は、値段は自分の上のセルからとれ」です。
わかりやすいように、高速化が発動するセルで解説します。
この計算式が、

こんな感じで進んでいき、次に計算するB4セルには、
| B4 | =IF(A4=A3,B3,VLOOKUP(A4,くだもの価格表!A:B,2,FALSE)) |
|---|
という式が入っていますよね。
この時の計算を丁寧に追うと、
- A4を見ます。わたしはりんごです。
- A3を見ます。前の人もりんごでした。
- 同じりんごなので、値段も一緒ですね。
- 前の人は200円です。
と、処理されるため、B4セルの計算ではVLOOKUPが起動しません。
この表では通常8回VLOOKUP関数が計算されるところ、このIF文を入れたことで、「りんごりんご」「いちごいちご」の2ヵ所でスキップされ、6回しか計算されなくなります。25%の処理時間削減!
これが簡単バージョンの高速化の内容です。
劇的な効果ではありませんが、式を書くのに手間がかからないというのが最大のメリットですので、気軽に使っていきましょう。
高速化できるときとそうでないとき
当たり前ですが、「連続した重複データの計算をスキップ」であるため、
ほとんどのデータが違う値になる場合は全く高速化しません。
「1人1個しか買わない商品で、購入者IDを顧客台帳から検索」
この時はほとんどスキップできませんからね。
ただ、この時にこの手法を使っても、遅くはならないので安心してください。
人間の感覚だとIFが入る分重くなりそうですが、
IFの判定と、(相対参照でちゃんとコピーされた)隣のセルを見るくらいは、
現代のコンピュータにとっては0と思っていいです。
逆にものすごく効果が出るのは、連続データが多いときです。
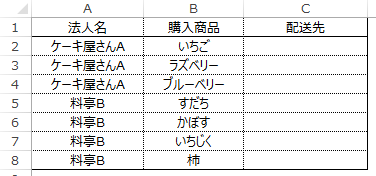
この配送先を法人台帳から検索する場合など、
ほぼ確実に連続になっているデータも、実務では割と遭遇します。
この例ではVLOOKUPが7回⇒2回に削減されているように、
連続データの多い表では、この手法でも数倍のスピードになりますので、どんどん使っていきましょう。
ソートしてからやると速い
一番上で扱ったこの表ですが、よくみると一番下にもりんごがありますね。
この手法を用いる場合は、商品名で並び替えてからやるとちょっとスピードアップします。今回の例では、りんご3つが一ヵ所に固まって、VLOOKUPの計算回数が6回⇒5回になりますからね
VLOOKUPに限らず、表形式のデータに何か作業をする際は、
並び替えを行うと効率が上がる場面が多いです。
積極的に活用してください。
まとめ
| B2 | =IF(A2=A1,B1,VLOOKUP(A2,くだもの価格表!A:B,2,FALSE)) |
|---|
という式を使って、
「同じデータが連続した場合に検索をスキップ」する高速化ができます。
書くのが簡単な割に結構効果があるので、気軽に使っていきましょう。
《超高速》参照先が順番に並んでいることを利用した高速化
次に「超高速!ただし使用条件あり」パターンを紹介します。
ちなみに見出しタイトルの通り、
使用条件は「参照先のデータがソート済みであること」です。
単刀直入にまずは答えの数式から。
先ほどの
| B2 | =VLOOKUP(A2,くだもの価格表!A:B,2,FALSE) |
|---|
この式を、
| B2 | =IF(VLOOKUP(A2,くだもの価格表!A:B,1,TRUE)=A2, VLOOKUP(A2,くだもの価格表!A:B,2,TRUE),"") |
|---|
こう書き替えると超高速化します。
これだけではなんのこっちゃだと思いますので、内容を説明していきますね。
近似一致検索を利用する
| B2 | =VLOOKUP(A2,くだもの価格表!A:B,2,FALSE) |
|---|
冒頭のこの式でもそうでしたが、VLOOKUPを実務で使う場面では、
第4引数はほとんど「FALSE」で使いますね。「完全一致」です。
じゃあここにTRUEを入れた「近似一致」の場合はどうなるかというと、
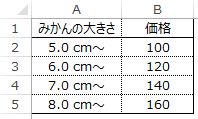
| VLOOKUP(6.2,みかんのサイズ表!A:B,2,TRUE) | =120 |
|---|
こんな感じの使い方ができる関数になります。
6~6.99…までは6が、
7~7.99…までは7が見つかったとみなして、
VLOOKUPが計算されるイメージですね。
さてこの使えそうでいまいち使う場面がない近似一致検索ですが、
実は超高速です。(理由は後述)
なので、この超高速な「近似一致」をうまく使って「完全一致」が再現できれば、
「完全一致」を高速化出来ることになります。
ではひとまず、目的の式をただ近似一致にしてみましょう。
| B2 | =VLOOKUP(A2,くだもの価格表!A:B,2,TRUE) |
|---|
これは近似一致の性質を照らし合わせると、
「みかんの値段を超高速で調べるけど、みかん以外の値段を伝えてくるかもしれない」関数です。
ってことは、「返ってきたのが本当にみかんの値段か」がわかれば、超高速な完全一致が完成しますよね?
そしてこの「返ってきたのが本当にみかんの値段か」も、同じVLOOKUPで調べることができます。
VLOOKUPの第3引数[見つかった時何列目を持ってくるか]を「1」にしてあげればいいのです。
「みかんが本当に見つかっているのであればみかんが返ってくる」という寸法です。
| VLOOKUP("みかん",くだもの価格表!A:B,1,TRUE)="みかん" |
これでみかんがA列にあるのかを判定できるということですね。
「A列からみかんを探して、見つかったらその行のA列を返す」という、一見不思議な式ですが、
「近似一致の結果が完全一致になっているかを判定」しているわけです。
と言うことで目的の式が完成しました。
| B2 | =IF(VLOOKUP(A2,くだもの価格表!A:B,1,TRUE)=A2, VLOOKUP(A2,くだもの価格表!A:B,2,TRUE),"") |
|---|
1列目を取ってこいVLOOKUPで、近似一致が完全一致になっているか確認し、
完全一致になっているならば、実際にn列目を持ってくるという計算手順です。
なお、再度注意しておきますが、「近似一致」はソート済みが前提の計算です。
より厳密には「くだもの価格表のA列が[昇順]に」並び変わっていないといけませんので、そこだけは絶対に忘れないようにしてください。
どのくらい速いのか
「超」高速とさっきから言っていますが、さてどれくらい速いのかというと、
「10万件から検索する場合、だいたい20~30倍」くらい速いです。圧倒的!
20秒くらいかかる処理が1秒を切るようになりますね。
しかもこの手法、「データ量が多いほど効果が高まる」というサイヤ人みたいなやつなので、100万件だと100倍くらい差がつきます。
もちろん「昇順にソート」されていることが前提であるため、
そうでない場合は「ソート」⇒「VLOOKUP」⇒「元に戻すソート」を計算時間に足さなければいけません。
ですが、検索より並び替えの方が基本は軽く、Excelのソートは優秀ですので、
「2回のソート」を加味しても、それでもトータルでこちらの方が速いです。
※ 人間感覚で「データ量が増えるとソートが重そう」と感じるかもしれませんが、
データ量と処理時間の相関は検索の方が大きいため、
データ量が多いほど、ソートを挟んだ方が高速化します。
ちょっと手間はかかりますが、効果は絶大ですので、
重いVLOOKUPには積極的にこの手法を取り入れていきましょう。
おまけ:MATCHも同様に高速化
まったく同じ理屈で、MATCH関数も高速化します。
VBAに組み込む場合はこっちの方が使いますね。
| B2 | =IF(INDEX(くだもの価格表!A:A,MATCH(A2,くだもの価格表!A:A,1))=A2,MATCH(A2,くだもの価格表!A:A,1),"") |
|---|
このようにMATCH関数の第3引数を「1:以下」で検索すると、
VLOOKUPの「近似一致」と同じ動きをします。
自分自身が返ってくるかのチェックにINDEX関数が必要になる以外は、
ほとんどVLOOKUP関数の場合と同じ処理ですね。
使い分け
《簡単》データが連続していることを活用した計算スキップ法
| B2 | =IF(A2=A1,B1,VLOOKUP(A2,くだもの価格表!A:B,2,FALSE)) |
|---|
《超高速》ソート済であることを活用した近似一致法
| B2 | =IF(VLOOKUP(A2,くだもの価格表!A:B,1,TRUE)=A2, VLOOKUP(A2,くだもの価格表!A:B,2,TRUE),"") |
|---|
この二つの方法を紹介しました。
さてこの使い分けですが、ひとまず速度面では圧倒的に近似一致法なので、
「参照元を並び替え出来ない」などがなければ、近似一致法を使っておけばOKです。
連続データ法は「参照元が昇順である保証ができない」ときと、
あとは「わざわざソートしたり、式を書くのが面倒なとき」用ですね。
使い捨ての資料で実行する1回かぎりのVLOOKUPとなると、
式を書いたり、ソートしに別シートを見に行くのも所要時間の内なので、
連続データが多そうなら、さっさと前者でやる方が楽だったりします。
おまけ:プログラミングにおける連続データの考え方について
速度面では「近似一致」方式が圧勝でしたが、この方法は「VLOOKUPの奥義」的な話です。
他にこの知識を使えるわけではありません。
対して「連続データの活用」方式は、他のことにも活かせる結構重要な知識です。
知識の大事さでいえばこちらに軍配が上がります。
| B2 | =IF(A2=A1,B1,~~ |
|---|
このような、「上のセルと比べて、同じなら計算をスキップする」IF文は、
SUMIF、COUNTIFの高速化を始め、多くのシート関数と併用できます。
また、この考え方は「プログラミングのループ処理」でもよく使います。
前ループで処理した値を記憶しておき、その値を使って次ループを高速化するのは、重要な手法になります。
表形式の巨大なデータを扱う際は、
- まずデータを並び替える
- キー(例では商品名)が変わったデータで計算を行う
- 同じキーが続いている部分は計算を行わず、ひとつ上のセル値を使う
という高速化ロジックは頻繁に使いますので、しっかりと仕組みを理解しておきましょう。
ちなみにですが、わざわざこの話題をVBAメインの本ブログで取り上げたのは、
「VBAにおいてワークシート関数を使うことが、マクロの高速化に直結する」からです。
特に今回のような「データの検索」に関しては、
MATCHやVLOOKUPより早い処理は、人力ではまず書けませんので、
WorksheetFunctionやFormulaに頼ることになります。
「シート関数を学び終わると次はVBA」という風土のせいか、
「プログラミングができれば、シート関数はいらなくなる」
みたいな勘違いをたまに見かけます。
しかし実際は逆で、高速化にはWorksheetFunctionやFormulaは必須であり、
むしろ上級者ほど、うまくシート関数を駆使したプログラムを書きます。
ワークシート関数はほかのプログラミング言語にはない強力なツールですから、
ガンガン使ってプログラミングしていきましょう。
おまけ:なぜ近似一致は速いのか
ほぼ豆知識ですが、なぜ近似一致が速いのか説明しますね。
と、はじめに断っておきますが、正確には「近似一致だから速い」のではなく、
「データがソート済なのを活用するから速い」です。
VLOOKUP関数の仕様として、「ソート済データの高速化が完全一致には組み込まれておらず、近似一致に組み込まれていた」ため、結果的に近似一致の方が速くなったというだけですので、そこは意識しておいてください。
※ 最新のExcelでは、完全一致でもこの手法が実装されており高速だったりします。
さて、並び替えが済んでいるデータから何かを探す場合、
「真ん中のデータを見て、どっち側にあるかを判断する」
を繰り返す検索方法をとることができます。
例えば10万件のデータから「325647」を探すとき、
ひとまず5万番目のデータだけ見て「229871」なのを確認し、
それより後ろを探しに行く、というのを繰り返すということです。
この方法、よくよく考えるとすごいスピードなのです。
最初の一回の判定で、5万件が検索済みになっているわけですから。
1個ずつ探す場合は5万回かかる処理が1回ですからね。
で、次は2万5000件が検索済みになり、次は1万2500と、
最初の方はすごいスピードで検索が終わっていきます。
しかも100万件のデータだったとしたら、
最初の1回で50万件が検索済みになるわけです。
「データ量が多いほど効果が高まる」というサイヤ人なのは、これが理由です。
「紙を43回折ると月に届く」と同じ、指数関数のパワーを使った理屈ですね。
この「真ん中をまず見て、どっちにいますか?法」を「二分探索」と呼びます。
英語だと「バイナリサーチ」という、ちょっとかっこいい名前です。
気が向いたら覚えてあげてください。